제목: GANBLR: A Tabular Data Generation Model [2021]
저자: Yishuo Zhang; Nayyar A. Zaidi; Jiahui Zhou; Gang Li
https://ieeexplore.ieee.org/document/9679177
GANBLR: A Tabular Data Generation Model
Generative Adversarial Network (GAN) models have shown to be effective in a wide range of machine learning applications, and tabular data generation process has not been an exception. Notably, some state-of-the-art models of tabular data generation, such a
ieeexplore.ieee.org
GAN을 기반으로 만든 모델들에는 CTGAN, TableGAN, medGAN 등과 같은 최신 표 형식 데이터 생성 모델들이 존재한다.
하지만 성능도 그렇고 여러 개선이 필요하다.
(1) 이 방법들은 모델의 성능에만 초점을 맞추고, 모델의 해석에 대한 것에는 제한적이다.
(2) 현 모델은 원시 특징에 대해서만 작동하고 데이터 생성 과정에서 feature끼리의 상호 작용에 대한 사전 지식을 활용하지 못한다.
=> naive Bayes와 Logistic Regression relationships에서 영감을 얻은 GAN 모델링을 제안한다.
"GANBLR"
Introduction
표 형식의 데이터 세트는 주로 범주형 및 숫자형 특징으로 구성된다.
이 데이터는 간단하지 않고 어려웠음.
이러한 다양한 feature 유형을 활용하는 방법에는 CTGAN, TableGAN, medGAN과 같은 모델이 최첨단 결과를 도출했음.
CTGAN은 범주형 특징을 일부 조건으로 간주하는 조건부 GAN 전략을 통해 표 형식의 데이터를 생성하고, 숫자 특징에는 가우스 혼합 모델 추정을 사용한다.
합성 데이터를 생성하기 위해 그라데이션 penalty가 있는 Wasserstein 거리를 활용한다.
TableGAN은 생성기와 판별기 단계 모두에서 컨볼루션 레이어를 사용하고 정보 손실 기반 목적 함수를 도입한다.
VanillaGAN의 G와 D는 특징 상호작용을 사전 지식으로 가지고 있을 수 있지만 암시적 특징 상호작용은 해석할 수 없다.
예를 들어, Salary와 Age가 높은 상관관계가 있다는 사전 지식이 있을 수 있지만, G는 이걸 포착할 수도 있고 아닐 수도 있다.
왜냐면 모델이 더 유용한 상호작용을 찾을 수 있기 때문이다.
우리는 이러한 한계를 기반으로 "다른 모델을 제너레이터로 활용할 수 있을까?"의 질문에 초점을 맞췄다.
해당 논문에선 생성기와 판별자 구성요소에 다른 접근방식을 사용하고자 한다.
생성기에 ANN(Artificial Neural Networks)를 놓기 보단, BN을 활용하는 방법을 차용할 것이다.
BN은 DAG (방향성 비순환) 모델로, 학습 과정에서 구조와 관련된 파라미터를 학습하는 과정을 포함한다. 구조를 지정하면 feature 의존성을 명시적으로 통합할 수 있다.
일반적인 BN 모델은 로그 확률 (LL)을 최대화 한다.
BN 모델에서는 확률을 계산하기 전에 x의 숫자 특징이 이산화 된다는 점을 유의해야 한다.
BN은 Generative model의 한 종류, 모델이 학습되면 합성 데이터를 생성할 수 있다.
BN에선 P(y_i, x_i)를 계산하여 분류자를 얻을 수도 있다.
이 뿐만 아니라 BN은 조건부 로그 확률인 (CLL)과 같은 판별 목적 함수를 최적화하여 학습할 수도 있다.
인기있는 모델 - Naive Bayes(NB).
BN은 GAN 모델에서 제너레이터로 사용하기에 완벽한 모델이라고 주장한다.
GAN 모델에서 BN을 사용할 때의 한 가지 단점은 범주형 속성을 가진 데이터만 처리할 수 있다는 것이다.
따라서 숫자 속성을 이산화한 다음 BN을 사용하여 샘플링하는 것이 숫자 속성을 직접 생성하는 것보다 효과적인 대안이 될 수 있다고 생각한다.
BN_d는 CLL을 최적화하여 훈련된 BN을 의미할 것이다.
또한 판별적으로 학습된 BN을 나타내되 실제 확률에 부합하도록 가중치를 BN_e로 제한한다.
연구 정리
BN_e를 생성자로, BN_d를 판별자로 사용하는 GANBLR
하지만 GANBLR은 범주형 속성을 가진 데이터 세트만 생성하는 것으로 제한된다는 점에 유의해라
Proposed Methods (GANBLR 구조)
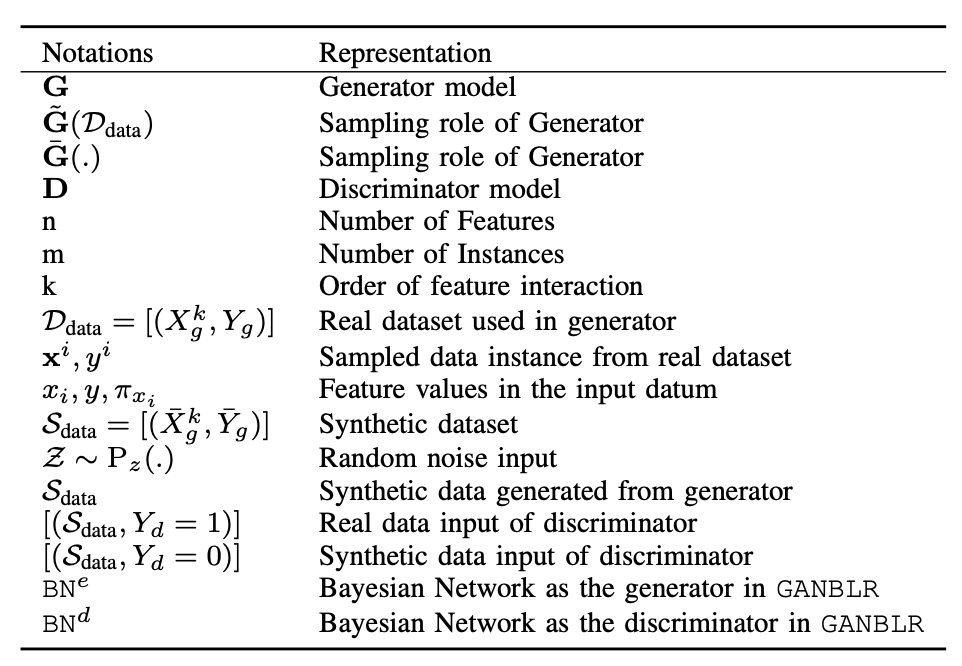
notation은 위와 같고, GANBLR의 구조는 다음과 같다.

생성기의 역할은 총 2개이다.
1. BN^e의 파라미터를 학습하는 것. -> 차별적 목적 함수를 최적화 (G^~ 의 역할임 : 빨간색 동그라미)
2. BN^e가 훈련된 후 데이터를 샘플링 하는 것. -> 최적화된 파라미터는 조건부 확률. 따라서 S_data를 샘플링 가능. (G^-의 역할임 : 파란색 동그라미)
따라서 과정은
생성기는 제약 조건 하에서 가중치를 차별적으로 최적화 하는 빨간색 동그라미로 작동한 다음, 합성 데이터 세트 생성을 위해 샘플링하는 파란색 동그라미로 작동한다.
판별기는 다시 베이지안 네트워크이다. (판별적으로 훈련되지만 가중치에 대한 제약이 없는 상태)
이 네트워크는 D 데이터와 S 데이터를 구별하는 방법을 학습한다.
'AI' 카테고리의 다른 글
| [개념 공부] Bayesian Network를 위한 통계 정리 (1) | 2024.10.13 |
|---|---|
| [논문 리뷰] 연속형, 불연속형 feature에서도 동작하는 GANBLR++ (1) | 2024.10.11 |
| [논문 리뷰] DAG-WGAN에 대하여 (1) | 2024.10.10 |
| [논문 리뷰] DAG-GAN에 대하여 (1) | 2024.10.10 |
| [논문 리뷰] 합성 데이터(EHR 데이터)에서의 GAN 정리 (0) | 2024.09.10 |