제목: Generating Multi-label Discrete Patient Records using Generative Adversarial Networks
저자: Edward Choi, Siddharth Biswal, Bradley Malin, Jon Duke, Walter F.Stewart, Jimeng Sun
Introduction
의료기관(HCO)에서 생성되는 전자 의료 기록, Electronic health recods(EHR)는 최근 굉장히 많은 상태.
하지만 EHR이 필요한 연구자들은 개인정보에 의해 쉽게 엑세스 할 수 없다.
여기서 보는 EHR 데이터의 가장 중요한 특징은 다음과 같다.
* 개인 식별자로 구성되어 있음. 즉, 민감한 의료 정보와 결합하여 개인정보 보호 문제를 유발함
따라서 이러한 데이터의 엑세스는 규제가 심할수밖에 없어진다.
그래서 보통 HCO에선 일반화, 억제 또는 무작위화를 통해 식별 가능한 속성들의 교란을 통해 개인정보 위험을 완화시키려고 함.
하지만 이 방법은 여전히 잔존 정보를 통해서 생성되기 때문에, 재식별 공격에 취약하다.
따라서 이 EHR 데이터를 지키기 위해선 합성 데이터를 생성하는게 방법이라고 다들 하는 것임.
그래서 해당 논문에선 GAN을 이용할 것이라고 함.
(GAN 설명은 패스) -> 주목할만한 점: GAN은 이산 변수의 분포를 학습하는 데는 사용되지 않았다고 함
암튼 이러한 GAN의 한계를 극복하여 EHR를 나타내는 고차원의 다중 레이블 이산 변수를 생성하는 신경망 모델인 medGAN을 만들었음
medGAN은 EHR 소스 데이터를 사용하여 AutoEncoder와 적대적 프레임워크의 조합을 통해 진단 또는 약물 코드와 같은 불연속형 특징의 분포를 학습하도록 설계했다고 한다.
논문 methodology를 간단하게 더 정리해보면 다음과 같다.
1. autoencoder + GAN의 결합 = "medGAN"
(binary와 count variables를 조작하는 데 큰 장점이 있다)
2. minibatch averaging을 이용했음 (기존 미니배치를 사용했을 때 생기는 GAN의 소수 훈련 샘플에 과적합하는 상황 방지)
Method
이제 EHR 데이터의 정리, 어떻게 medGAN을 만들었는지, 그리고 minibatch averaging은 무엇인지 알아보도록 하자.
1. Description of EHR Data and Notations
(EHR 데이터 표현)
- 데이터에 |C|개의 discrete variables(e.g., 진단, 투약, 혹은 시술 코드)가 있다고 가정.
- 이제 데이터의 변수들을 어떻게 표현할 것이냐, i차원에 대해서 두가지로 표현할 것임
a) 카운트 벡터로 표현 : x ∈ ℤ₊^|C|
b) 이진 벡터로 표현 : x ∈ {0,1}^|C|
- 여기서 i 차원은 해당 변수의 부재(0) 또는 발생(1)로 나타낼 것임
2. Generative Adversarial Network (GAN)
GAN의 기본적인 개념은 생성자와 판별자의 경쟁 구도.
최종적으로 나오는 value를 함수화를 시켜서 표현하면 다음과 같다.
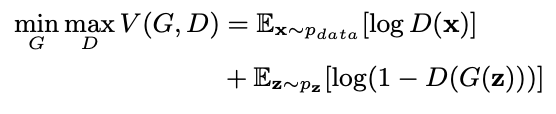
P_data는 real sample의 distribution
p_z는 random prior의 distribution
G와 D에 대하여 각각의 parameter을 수정하는 공식은 다음과 같다.
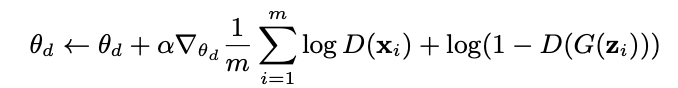
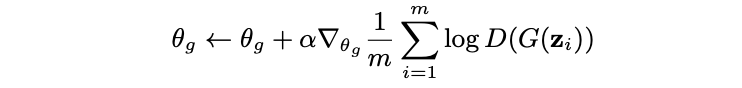
m은 미니 배치 개수이다.
3. medGAN
가장 중요한 medGAN은 어떻게 구성되었는가
생성기 G는 판별기 D의 오류 신호에 의해 역전파를 통해 학습이 되기 때문에, 원래 GAN은 불연속적인 환자 기록 x를 연속적인 값으로 근사화 하는 방법만 학습할 수 있었다.
하지만 이러한 한계를 autoencoder을 활용하여 완화할 수 있다.
autoencoder -> 주어진 샘플을 저차원 공간에 투영한 다음, 다시 원래 공간에 투영하도록 학습된다.
즉, autoencoder로 이산 변수의 특징을 학습 -> G의 연속 출력을 디코딩하는 데 적용.
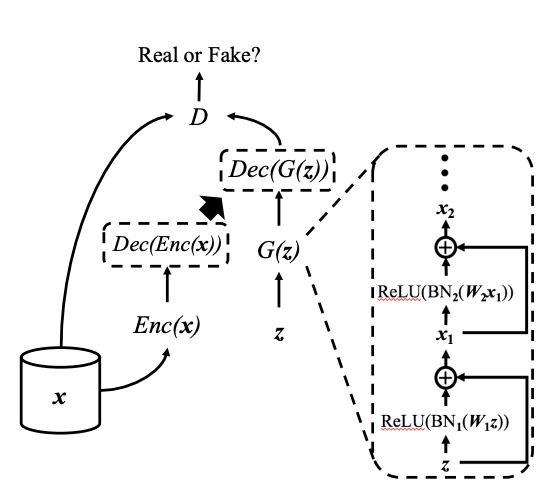
Fig 1에서 볼 수 있듯, 오토인코더는 Enc(x;θ_enc)와 Dec(Enc(x);θ_dec)를 포함하고 있으며 오토인코더는 reconstruction error을 최소화 하는 것을 목표로 한다.
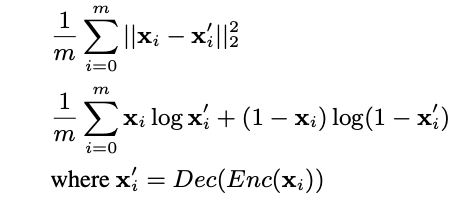
G와 D 각각의 parameter을 훈련하는 방법은 기존 GAN과 유사하다.

이때 중요한 것은 D가 연속형 값이 아닌 불연속형 값으로 훈련되도록 하기 위해 Dec(G(z))의 값을 가까운 정수로 반올림할 수 있다는 것!
반올림을 사용했을 때와 사용하지 않았을 때를 모두 실험한 결과, 반올림을 사용했을 때 더 나은 예측을 했음.
4. Minibatch Averaging
G의 목표: 판별자 D를 속일 수 있는 샘플을 생성하는 것.
따라서 G는 다양한 합성 출력을 생성하는 대신 동일한 합성 출력에 서로 다른 무작위 전제 z를 매핑하는 방법을 택한다.
(이것을 모드 붕괴라고 함)
"모드 붕괴"는 G가 다양한 출력을 생성하지 않고, 특정한 하나의 출력(또는 소수의 출력)만을 생성하려고 하는 문제이다.
이렇게 되면 G는 서로 다른 입력 z에 대해 거의 같은 출력을 만들게 됨.
이는 G가 다양한 데이터를 생성하는 데 실패했다는 것을 의미하게 된다.
모드 붕괴의 원인은 GAN의 최적화 전략 때문.
일반적으로 GAN은 min_G max_D V(D,G)의 min-max문제를 해결하려고 함.
(여기서 V(D,G)는 D가 가짜와 진짜 데이터를 구별하는 능력과 G가 D를 속이는 능력을 나타내는 손실함수)
즉, D가 먼저 최대화를 수행하고, G가 그 다음에 최소화를 수행하는 식으로 GAN이 이론적으로 이상적인 순서대로 학습하지 못함.
이로인해 G는 D를 속이기 위한 가장 쉬운 방법을 찾게 되는데, 그 결과가 모드 붕괴로 나타날 수 있는 것이다.
해당 논문에선 이러한 모드 붕괴를 막기 위해 minibatch averaging을 사용함.
D는 실제 샘플과 가짜 샘플을 분류하면서 각각 실제 샘플 x1, x2, ...의 미니배치와 가짜 샘플 G(z1), G(z2), ...의 미니배치를 볼 수 있다.
판별할 샘플이 주어지면 미니 배치 판별은 잠재 공간에서 주어진 샘플과 미니 배치의 모든 샘플 사이의 거리를 계산한다. 반면, 미니 배치 평균은 미니배치 샘플의 평균을 D에 제공하여 다음과 같이 목표를 수정한다.

여기까지가 해당 논문에서 사용한 medGAN method에 관한 부분들이다.
실제로 구현해놓은 github 코드가 있으니, 코드 분석도 추천한다.
'AI' 카테고리의 다른 글
| [논문 리뷰] DAG-GAN에 대하여 (1) | 2024.10.10 |
|---|---|
| [논문 리뷰] 합성 데이터(EHR 데이터)에서의 GAN 정리 (0) | 2024.09.10 |
| 베이지안 네트워크 이해하기 (1) - BN으로 합성 데이터 만들기 실습 (0) | 2024.08.21 |
| [딥러닝] Numpy Basic Concepts (0) | 2024.04.16 |
| [딥러닝] 기초 - Learning Curves 이해하기 (0) | 2024.04.13 |