제목 : Edge Computing : Vision and Challenges
저자 : Weisong SHi, Jie Cao, Quan Zhang, Youhuizi, and Lanyu Xu
저번엔 Challenges and opportunities 이전까지 읽었다.
이전 글에선 엣지 컴퓨팅의 비전을 실현하기 위해선 시스템과 네트워크 커뮤니티가 함꼐 협력해야 한다고도 말했다. (협력 엣지)
이제는 이러한 과제를 자세히 요약하고, 프로그래밍 가능성, 네이밍, 데이터 추상화, 서비스 관리, 개인정보 보호 및 보안, 최적화 메트릭 등 추가 연구 가치가 있는 부분을 소개하도록 한다.
IV. Challenges And Opportunities
A. Programmability
클라우드 컴퓨팅에선 사용자가 코드를 프로그래밍해서 클라우드에 배포한다.
일반적으로 프로그램은 클라우드에서만 실행되기 때문에 하나의 프로그래밍 언어로 작성되고 특정 대상 플랫폼에 맞게 컴파일 된다.
그러나 엣지 컴퓨팅에선 계산이 클라우드에서 오프로드되고 엣지 노드는 heterogeneous platform일 확률이 높다.
따라서 각 노드의 런타임은 서로 다르고, 프로그래머는 엣지 컴퓨팅 패러다임에서 배포될 수 있는 application을 작성하는 데 큰 어려움을 겪게 된다.
(즉, 엣지가 성능도 용량도 각각 다 다른 디바이스인데 여기서 어떻게 프로그램을 돌릴 것이냐를 문제삼는 중임.)
이를 해결하기 위해서 데이터 전파 경로를 따라 데이터에 적용되는 일련의 functions/computing으로 정의되는 컴퓨터 스트림 개념을 제안한다.
functions/computing은 애플리케이션의 전체 또는 일부 기능일 수 있는데, 애플리케이션이 컴퓨팅이 수행되어야 하는 위치를 정의하는 한 경로의 어느 곳에서나 컴퓨팅이 수행될 수 있다.
(The functions/computing could be entire or partial functionalities of an application, and the computing can occur anywhere on the path as long as the application defines where the computing should be conducted.)
computing stream은 소프트웨어 정의 컴퓨팅 flow로, 데이터 생성 디바이스, 엣지 노드, 클라우드 환경에서 분산되고 효율적인 방식으로 데이터를 처리할 수 있다. 엣지 컴퓨팅에 정의된 대로, 많은 컴퓨팅이 중앙 클라우드가 아닌 엣지에서 수행될 수 있는데, 이 경우 컴퓨팅 스트림은 사용자가 어떤 functions/computing을 수행해야 하는지, 컴퓨팅이 엣지에서 발생한 후 데이터가 어떻게 전파되는지 결정하는 데 도움을 줄 수 있다.
functions/computing distribution metric은 latency-driven, energy cost, TCO 그리고 하드웨어/소프트웨어 specified limitation이 될 수도 있다.
computing stream을 배포하면, 데이터가 데이터 소스에 최대한 가깝게 계산되고 데이터 전송 비용을 줄일 수 있을 것으로 기대된다.
컴퓨팅 스트림에서는 함수를 재할당할 수 있으며, 함수와 함께 데이터와 상태도 재할당해야 합니다. 또한, 협업 문제(예: 동기화, 데이터/상태 마이그레이션 등)는 엣지 컴퓨팅 패러다임의 여러 계층에서 해결해야 한다.
B. Naming
엣지 컴퓨팅에서 중요한 가정 중 하나는 사물의 수가 엄청나게 많다는 것.
엣지 노드의 최상위에는 수많은 애플리케이션이 실행되고 있으며, 각 애플리케이션은 서비스 제공 방식에 대한 고유한 구조를 가지고 있다.
모든 컴퓨터 시스템과 마찬가지로 엣지 컴퓨팅의 네이밍 체계는 프로그래밍, 주소 지정, 사물 식별 및 데이터 통신에 매우 중요하다.
하지만, 효율적인 명명 메커니즘은 아직 없음.
엣지 컴퓨팅을 위한 Naming은 사물의 이동성, 동적인 네트워크 토폴로지, 개인 정보 보호 및 보안 보호는 물론 엄청나게 많은 양의 신뢰할 수 없는 사물을 대상으로 하는 확장성을 처리해야 하는 과제를 앞두고 있다.
(Naming 1.) DNS 및 유니폼 리소스 식별자와 같은 기존의 명명 메커니즘은 현재 대부분의 네트워크를 매우 잘 충족한다.
하지만 엣지에 있는 대부분의 사물이 이동성이 높고 리소스의 제약을 받을 수 있기 때문에 동적인 엣지 네트워크에 서비스를 제공하기에는 유연성이 부족하다.
또한 네트워크 엣지의 일부 리소스 제약이 있는 사물의 경우 (Naming 2.) IP 기반 명명 체계는 복잡성과 오버헤드를 고려할 때 지원하기에는 너무 무거울 수 있다.
(Naming 3.) Named Data Networking(NDN)과 같은 새로운 명명 메커니즘도 엣지 컴퓨팅에 적용될 수 있다.
NDN은 콘텐츠/데이터 중심 네트워크에 계층적으로 구조화된 이름을 제공하며, 서비스 관리에 있어 인간 친화적이고 엣지에 우수한 확장성을 제공한다.
Q. What is NDN

NDN은 다른 네트워크 아키텍처와 구별되는 세 가지 핵심 개념이 있습니다.
첫째, 애플리케이션 이름 데이터와 데이터 이름이 네트워크 패킷 전달에 직접 사용되며, 소비자 애플리케이션은 원하는 데이터를 이름으로 요청하므로 NDN의 통신은 소비자 중심으로 이루어집니다.
둘째, NDN 통신은 데이터 중심 방식으로 보호되며, 즉 각 데이터 조각(데이터 패킷이라고 함)은 생산자가 암호화하여 서명하고 민감한 페이로드 또는 이름 구성 요소도 프라이버시를 위해 암호화할 수 있으므로 소비자는 패킷을 가져오는 방식에 관계없이 패킷을 확인할 수 있습니다.
셋째, NDN은 포워더가 각 데이터 요청(관심 패킷이라고 함)에 대한 상태를 유지하고 해당 데이터 패킷이 돌아오면 해당 상태를 지우는 상태 저장 포워딩 플레인을 채택하여 지능형 포워딩 전략을 가능하게 하고 루프를 제거합니다.
인터넷은 주로 정보 유통 네트워크로 사용되기 때문에 IP와 잘 어울리지 않으며, 미래 인터넷의 '얇은 허리'는 숫자로 주소가 지정된 호스트가 아닌 네임드 데이터를 기반으로 해야 한다는 전제를 깔고 있습니다.
기본 원칙은 통신 네트워크는 사용자가 데이터를 검색할 특정 물리적 위치, 즉 호스트를 참조할 필요 없이 필요한 데이터, 즉 콘텐츠에 집중할 수 있도록 해야 한다는 것입니다. 이러한 동기는 현재 인터넷 사용의 대부분("트래픽의 90% 수준")이 소스에서 다수의 사용자에게 배포되는 데이터로 구성되어 있다는 사실에서 비롯됩니다.[4] 네임드 데이터 네트워킹은 콘텐츠 캐싱을 통해 혼잡을 줄이고 전송 속도를 개선하며, 네트워크 디바이스를 보다 간편하게 구성하고 데이터 수준에서 네트워크에 보안을 구축하는 등 다양한 이점을 제공할 수 있는 잠재력을 가지고 있습니다.
하지만 블루투스와 지그비 등 다른 통신 프로토콜에 NDN을 적용하기 위해선 추가적인 프록시가 필요하다.
NDN과 관련된 다른 문제는 보안인데, 서비스 제공업체와 사물 하드웨어 정보를 분리하는 것이 힘들기 때문이다.
(Naming 4.) MobileFirst는 이름과 네트워크 주소를 분리하여 더 나은 이동성을 지원하며 사물의 이동성이 높은 엣지 서비스에 적용하면 매우 효율적이다.
하지만 MobileFIrst Naming을 사용하기 위해선 글로벌 고유 식별자(GUID)를 사용해야 하며, home 환경과 같은 고정 정보 통합 서비스에는 필요 없다. + GUID는 인간친화적이지 않아서 관리가 어렵다.
=> 홈 환경과 같이 상대적으로 작고 고정된 엣지에서는 (Naming 5.) 엣지OS가 각각의 사물에 네트워크 주소를 할당하도록 하는 것이 해결책이 될 수 있다.
하나의 시스템에서 각 사물은 위치(어디), 역할(누가), 데이터 설명(무엇)과 같은 정보를 설명하는 고유한 인간 친화적인 이름을 가질 수 있습다.(예: "kitchen.oven2.temperature3").
그런 다음 edgeOS는 그림 5와 같이 이 사물에 식별자와 네트워크 주소를 할당한다.
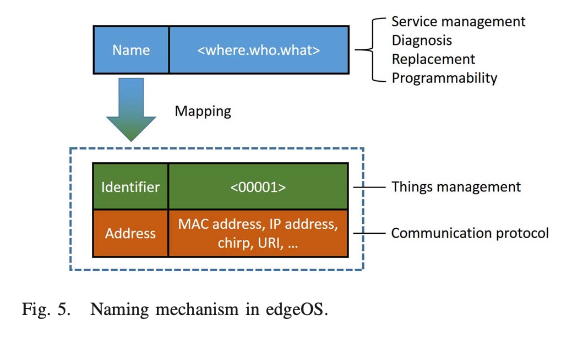
(장점) 사용자와 서비스 제공자 입장에서는 이러한 네이밍 메커니즘을 통해 매우 쉽게 관리할 수 있다.
예를 들어, 사용자는 "거실 (어디에) 있는 천장 조명 (누구)의 전구 3(무엇)이 고장났습니다"와 같은 메시지를 edgeOS로부터 수신하면 오류 코드를 검색하거나 새 전구의 네트워크 주소를 다시 파악할 필요 없이 고장난 전구를 직접 교체할 수 있게 된다.
(장점2) 이러한 네이밍 메커니즘은 서비스 제공업체에게 더 나은 프로그래밍 기능을 제공하는 동시에 서비스 제공업체가 하드웨어 정보를 얻는 것을 차단하여 데이터 프라이버시와 보안을 더 잘 보호할 수 있다.
고유 식별자와 네트워크 주소는 사람에게 친숙한 이름에서 매핑될 수 있다.
식별자는 edgeOS에서 사물 관리에 사용되는데, IP 주소나 MAC 주소와 같은 네트워크 주소는 블루투스, 지그비, 와이파이 등 다양한 통신 프로토콜을 지원하는 데 사용된다.
하지만 여전히 도시 수준의 시스템과 같이 매우 동적인 환경을 대상으로 할 때는 아직까지 미해결 문제이며 커뮤니티에서 더 연구할 가치가 있다.
C. Data Abstraction
데이터 추상화는 유선 센서 네트워크와 클라우드 컴퓨팅 패러다임에서 많이 논의되고 연구되어왔다.
IoT에서는 네트워크에 엄청난 수의 데이터 생성기가 존재하게 되는데, 이 대부분의 things는 대부분 주기적으로 감지된 데이터만 게이트웨이에 전송한다.
쉽게 예를 들어보면, 집에 있는 보안 카메라가 계속 영상을 녹화하여 게이트웨이로 전송할 수 있지만, 실제로는 일정 시간 동안만 데이터베이스에 저장했다가 최신 영상으로 덮어씌워지곤 한다.
이렇게 엣지 컴퓨팅에선 사람의 개입을 최소화하고 엣지 노드가 모든 데이터를 소비/처리하고 능동적인 방식으로 사용자와 상호 작용해야 한다고 상상한다.
이 경우 노이즈/저품질 제거, 이벤트 감지, 개인정보 보호 등 게이트웨이 수준에서 데이터를 전처리해야 하는데, 이렇게 처리된 데이터는 향후 서비스 제공을 위해 상위 계층으로 전송된다.
여기엔 수많은 문제가 발생한다.
첫 번째, 다양한 사물에서 보고되는 데이터의 형식이 다양하다.
게이트웨이에서 실행되는 application은 원시 데이터로부터 개인정보 보호 및 보안을 위해 블라인드 처리 되어있어야 한다.
또한 통합 데이터 테이블에서 관심 있는 지식을 추출해야 한다. ID, 시간, 이름, 데이터 형태 등.
그러나 센싱된 데이터의 세부 정보가 숨겨져 있어 데이터의 유용성에 영향을 미칠 수 있다.
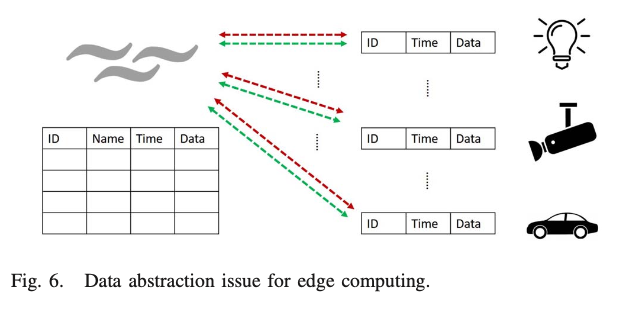
두 번째, 데이터 추상화 정도를 결정하기가 어려울 때가 있다.
원시 데이터를 너무 많이 걸러내면 일부 애플리케이션이나 서비스가 충분한 지식을 학습하지 못할 수 있다.
또한 대량의 원시 데이터를 보관하려면 데이터 저장에 문제가 생길 수 있다.
세 번째, 엣지 디바이스가 보고하는 데이터는 정밀도가 낮은 센서, 위험 환경, 불안정한 무선 연결 등으로 인해 때때로 신뢰할 수 없는 경우가 있다.
이 경우 신뢰할 수 없는 데이터에서 유용한 정보를 추상화하는 방법은 어려운 난제가 된다.
다섯 번째, 사물에 대한 적용 가능한 연산.
데이터를 수집하는 것은 애플리케이션에 서비스를 제공하기 위한 것이며, 애플리케이션은 사용자가 원하는 특정 서비스를 완료하기 위해 사물을 제어할 수 있어야 한다.
데이터 표현과 운영을 결합한 데이터 추상화 계층은 edgeOS에 연결된 모든 사물에 대한 공용 인터페이스 역할을 하게 된다.
또한 사물의 이질성으로 인해 데이터 표현과 허용되는 연산은 매우 다양하다는 것.
D. Optimization Metrics
엣지 컴퓨팅에서는 서로 다른 연산 능력을 가진 여러 계층이 존재한다.
이 중에서 workload 할당은 큰 문제가 되는데, workload를 처리할 레이어 또는 각 파트에 할당할 작업 수를 결정해야 한다.
예를 들어서 각 레이어에 workload를 균등하게 분배하거나 각 레이어에서 가능한 한 많은 작업을 완료하는 등 워크로드를 완료하기 위한 여러 가지 할당 전략이 있다.

할당 전략 중 극단적인 경우는 엣지에서 완전히 운영되거나 클라우드에서 완전히 운영되는 경우.
최적의 할당 전략을 선택하기 위해 이 섹션에서는 지연 시간, 대역폭, 에너지 및 비용을 비롯한 몇 가지 최적화 메트릭에 대해 설명한다.
1) Latency
클라우드 컴퓨팅의 서버는 높은 연산 능력을 제공.
그러나 지연 시간은 계산 시간에 의해서만 결정되는 것이 아니다.
WAN 지연이 길면 실시간 상호 작용이 많은 애플리케이션의 동작에 큰 영향을 미칠 수 있다. 지연 시간을 줄이려면 네트워크 엣지에 있는 사물에 충분한 연산 능력을 갖춘 가장 가까운 레이어에서 워크로드를 완료하는 것이 좋다.
(예시) 스마트 시티 속에서 실종 아이 찾기
모든 사진을 업로드하는 대신, 휴대폰을 활용하여 로컬 사진을 먼저 처리 -> 실종 아이의 정보를 전송
but 가장 가까운 물리적 계층이 항상 좋은 옵션은 아니다. 불필요한 대기 시간을 피하기 위해 리소스 사용량 정보를 고려, 논리적으로 최적의 계층을 찾아야 한다.
(예시) 핸드폰에서 특정 어플을 실행 -> 핸드폰의 리소스가 사용 중 -> 가까운 게이트웨이 혹은 마이크로 센터에 사진을 업로드하는 것이 좋다.
2) Bandwidth
높은 대역폭은 대용량 데이터의 경우 전송 시간을 줄일 수 있다.
단거리 전송의 경우 : 고대역폭 무선 액세스를 구축하여 데이터를 엣지로 전송할 수 있다.
(엣지에서 워크로드를 처리할 수 있다면 클라우드에서 작업할 때보다 지연 시간을 크게 개선할 수 있다.)
=> 합리적인 할당 전략을 선택할 수 있도록 워크로드별로 메트릭에 우선순위(또는 가중치)를 부여해야 한다.
또한 비용 분석은 런타임에 수행해야 합니다. 동시 워크로드의 간섭과 리소스 사용량도 고려해야 한다.
'Infrastructure > Networking' 카테고리의 다른 글
| Network Edge란 (3) | 2024.03.18 |
|---|---|
| Internet 정의, Protocol 정의 (1) | 2024.03.18 |
| [통신 네트워크 설계] Network Performance (0) | 2024.03.11 |
| [논문 리뷰] #1. Edge Computing : Vision and Challenges (1) | 2024.03.10 |
| [통신 네트워크 설계] Connecting Devices 정리 (0) | 2024.03.10 |